DocAgent
An AI document processing agent that extracts structured data from any PDF, flags risks and discrepancies, and delivers plain-English summaries — supporting invoices, contracts, legal filings, and scanned documents via OCR.
Overview
What is DocAgent?
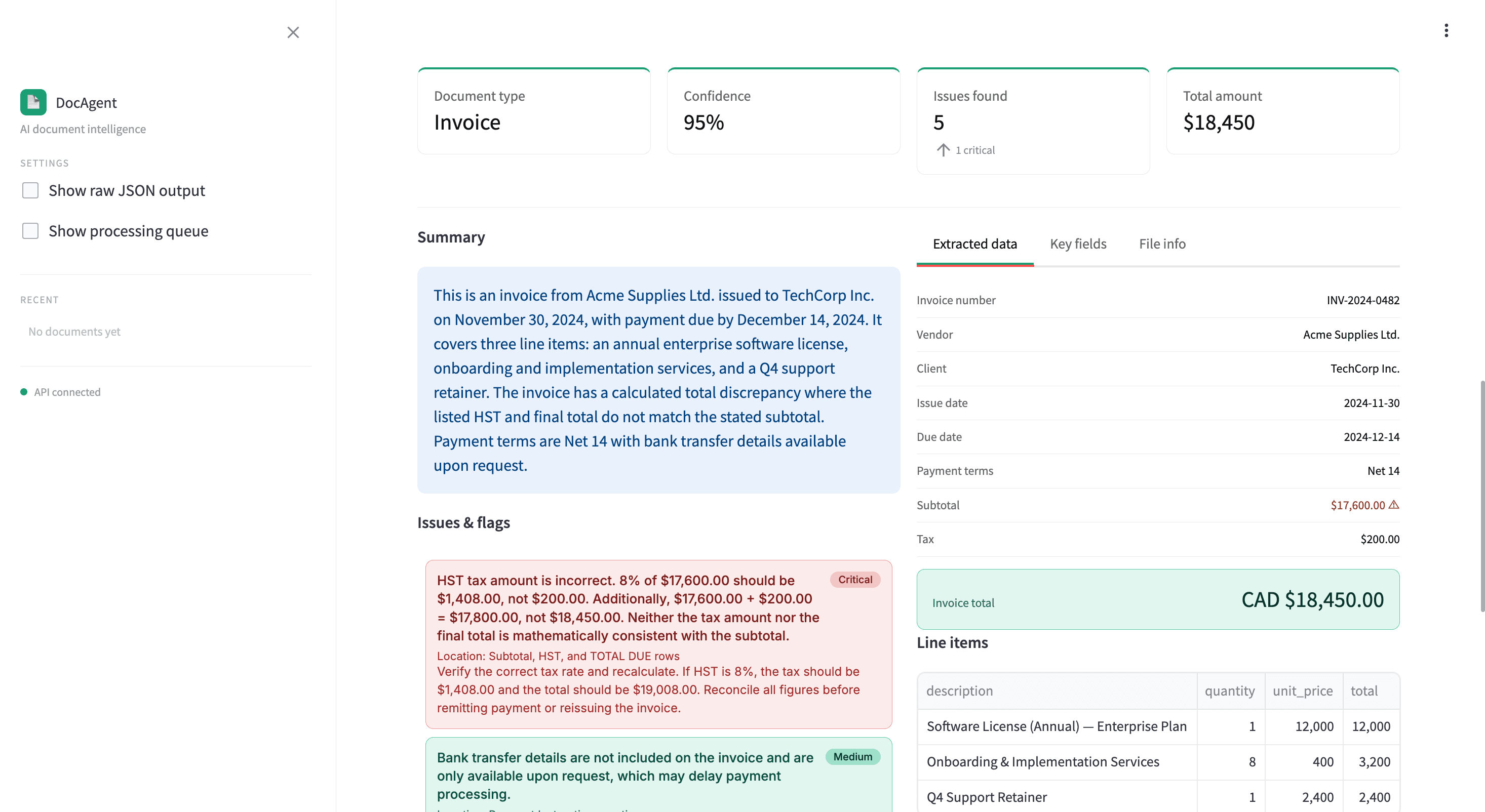
DocAgent is a complete, deployable AI document processing tool built for legal, finance, and real estate workflows. Built as the technical foundation for Refraxis — document processing systems for Canadian accounting firms, legal practices, and municipalities. Drop in any PDF and it extracts structured data — parties, dates, amounts, obligations, clauses — validates it against strict Pydantic schemas, and returns a plain-English summary alongside a ranked list of flagged issues.
The pipeline handles the full range of real-world document problems. Scanned documents are detected using multiple signals and automatically routed through Tesseract OCR. Password-protected and corrupted files are rejected early with clear error messages. Large documents are split at natural boundaries, each section summarised independently, then combined — so nothing gets dropped or truncated.
When the LLM returns malformed output, the system retries with a progressively stricter prompt rather than failing silently. Every processing job is logged to a SQLite queue with full status tracking, so failed jobs are always recoverable. The UI stores session history so past documents are instantly accessible from the sidebar without reprocessing.
The Problem
Legal and finance teams spend hours manually reviewing contracts and invoices — checking for math errors, flagging risky clauses, extracting key dates and parties into spreadsheets. Scanned documents make it worse. And when something is missed — a liability cap buried in section 4, a payment term that compounds at 60% annually — the cost is real.
The Solution
A document agent that reads the entire file — text or scanned — extracts every material field into structured JSON, and surfaces issues ranked by severity before a human ever opens the document. Critical flags like arithmetic errors or asymmetric termination clauses appear immediately, with the exact location and a specific recommendation attached.
What I Learned
Scanned PDF detection cannot rely on character count alone. A single-page cover sheet with one line of text would be misidentified as scanned. The right approach combines image presence, text object count, and character density relative to page area — multiple independent signals that all need to agree before routing to OCR.
LLMs return bad JSON more often than expected in production, and retrying with the same prompt produces the same result. A two-prompt strategy — friendly initial prompt, then a strict retry that explicitly forbids every formatting mistake observed — solves 95% of failures. The retry prompt is a product decision, not just error handling.
Truncating large documents is the wrong default. The middle of a contract often contains the most material clauses — liability caps, IP ownership, indemnification. Chunking at natural boundaries (page breaks → paragraphs → sentences) and summarising each section independently preserves everything while staying within the model's context window.
Next Project
Cadence